Tutorial
In this tutorial, we will use bxl to gather and generate all the index data of a target and its dependencies. Along the way we will cover query, analysis, extracting information from an analysis result, running an action and materializing artifacts.
This tutorial has 4 parts:
- Part 0: Hello world
- Part 1: Query the targets
- Part 2: Do analysis and extract the information from the analysis result
- Part 3: Run action and materialize the artifacts
Environment
For all following tutorial, we assume you are in [examples/bxl_tutorial](
https://github.com/facebook/buck2/tree/main/examples/bxl_tutorial
) folder.
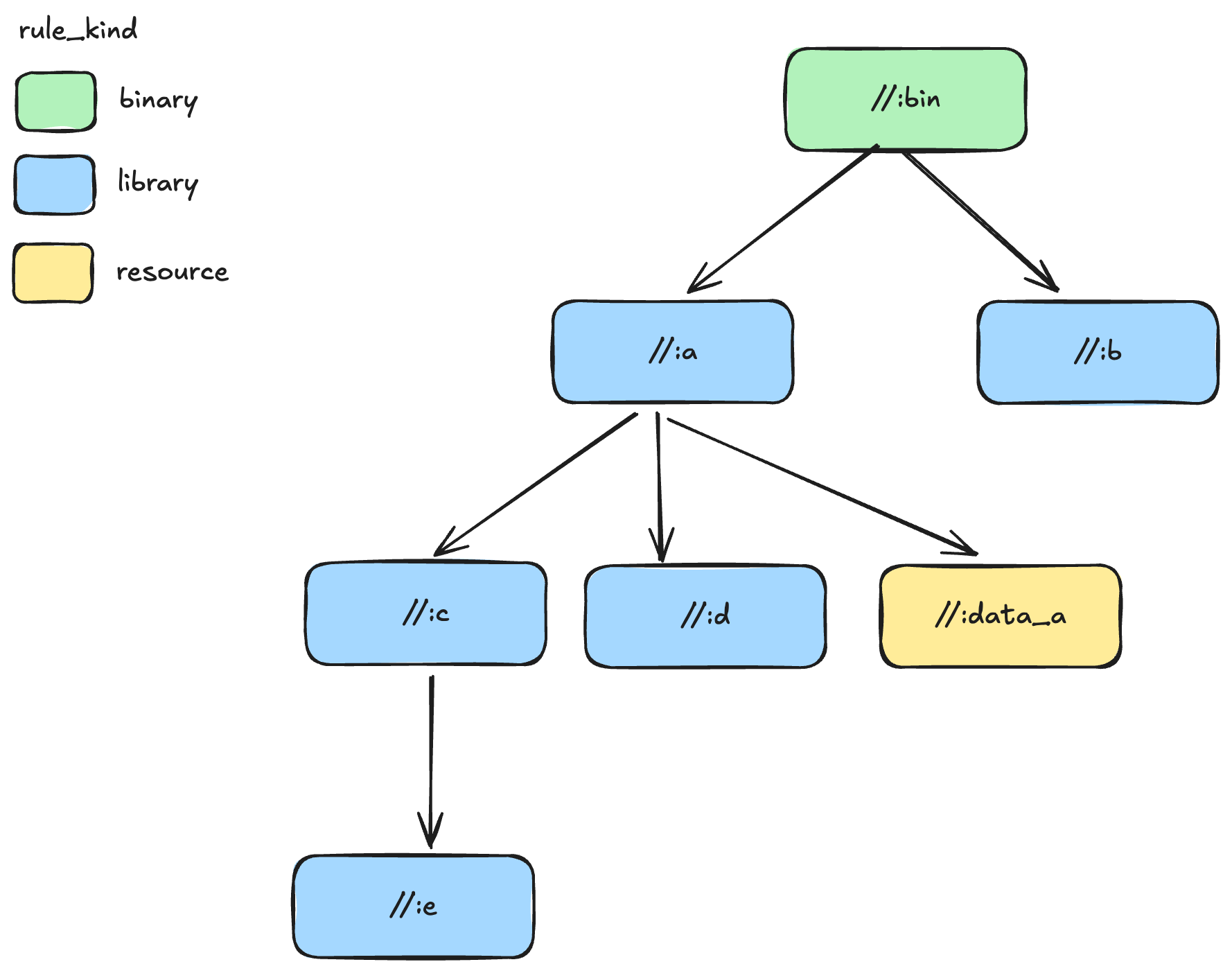
This folder contains a buck2 project with several targets. These targets form this dependency graph:
Part 0:
In this part, we will use bxl to write a "Hello world" program. We show how to define a function that receives arguments from the CLI and how to run it.
First, let's create a file named hello_world.bxl and open it.
Then, we define a bxl function which can be called by buck2 bxl:
main = bxl_main(
impl = _main,
cli_args = {},
)
bxl_main takes 2 arguments:
implimplementation of this bxl main functioncli_argswe can define the arguments here
Lets run the bxl script to give it a try. The command is in the format
buck2 bxl [file_path_to_bxl_file]:[bxl_main_function_name]. For this case it
looks like this:
buck2 bxl hello_world.bxl:main
As expected, we get this error:
Error evaluating module: `root//hello_world.bxl`
Caused by:
error: Variable `_main` not found, did you mean `main`?
--> hello_world.bxl:2:12
|
2 | impl = _main,
| ^^^^^
|
This is because we haven't defined the implementation function _main here.
Let's do that:
def _main(ctx: bxl.Context):
ctx.output.print("Hello world!")
main = bxl_main(
impl = _main,
cli_args = {},
)
Now if we run buck2 bxl hello_world.bxl:main, we will see the Hello world!
in the console.
For this, function _main must be defined to accept the argument ctx with
type bxl.Context
We can also use cli_args to pass cli args to bxl.
These args can be accessed in the main function via
ctx.cli_args.
Here is an example
def _main(ctx: bxl.Context):
ctx.output.print("Hello " + ctx.cli_args.project_name + "!")
main = bxl_main(
impl = _main,
cli_args = {
"project-name": cli_args.string(),
},
)
We can call bxl like this:
buck2 bxl hello_world.bxl:main -- --project-name buck2
We will see Hello buck2! in the console.
Part 1:
Imagine we're generating index data for a Language Server Protocol (LSP). In our example, this index data is available in the build graph and originates from the "index" sub-target of each "library" and "binary" target. We'll utilize BXL to aggregate all the index data from a given target's dependencies into a single dataset.
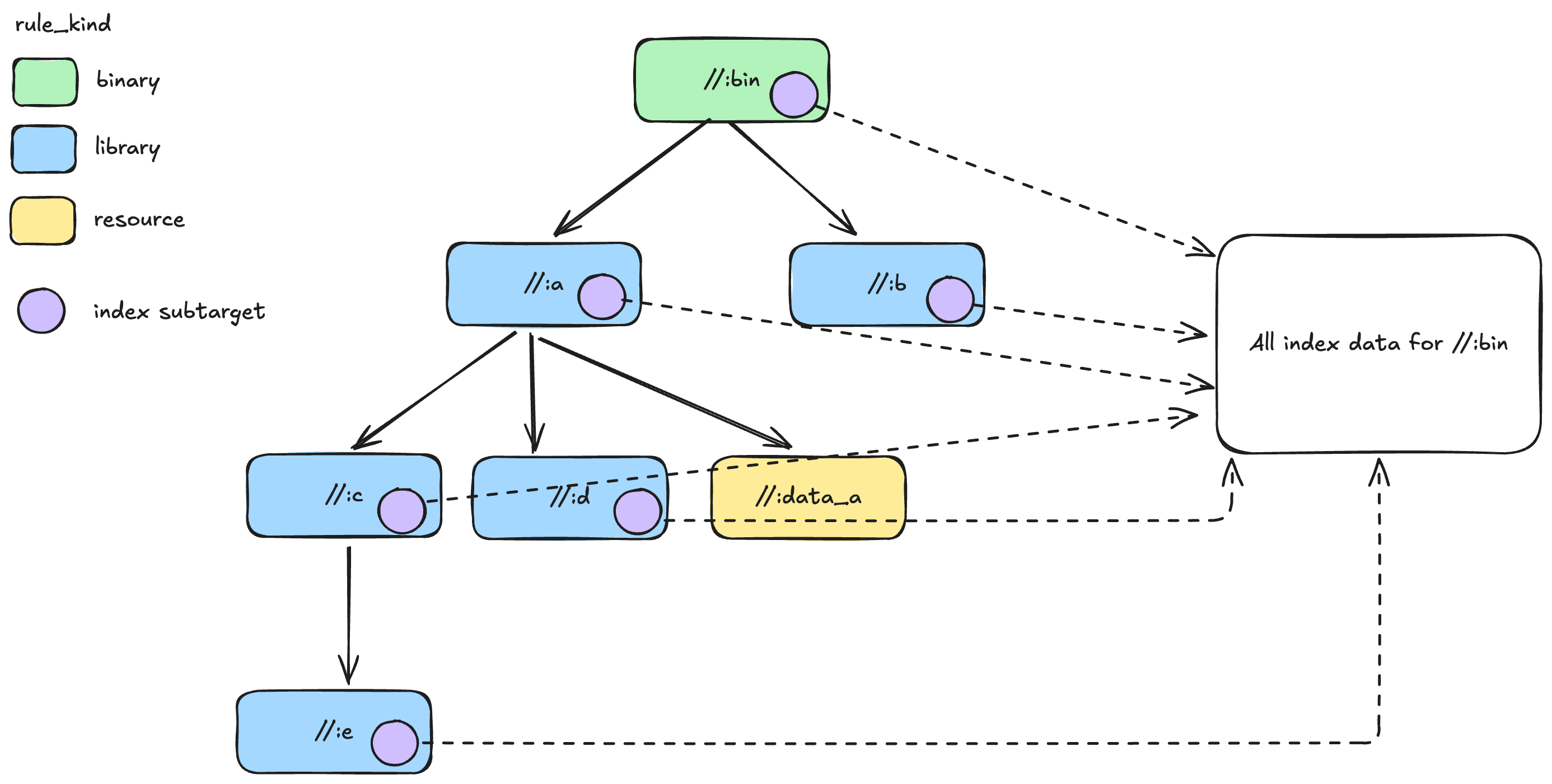
In this part, we will use bxl query and filter to get the targets that we want to be used for generating index data. Along the way, we will work with target universes and queries to get exactly the targets we need.
Let's describe the problem we want to solve. We already have (per target graph above) different types of targets: binaries, libraries, and resources. We only want the targets that are of type "binary" or "library", since "resource" targets do not contain index data.
First, create a new file called generate_index.bxl with this basic script:
def _main(ctx: bxl.Context):
ctx.output.print(ctx.cli_args.target)
main = bxl_main(
impl = _main,
cli_args = {
"target": cli_args.target_label(),
},
)
We use this command to run our script:
buck2 bxl generate_index.bxl:main -- --target //:bin
We need to get all the deps of this target, we do that using the target universe for this target:
universe = ctx.target_universe(ctx.cli_args.target)
This will return a TargetUniverse type. Then
we get the all the targets from target universe:
all_targets = universe.universe_target_set()
We can print it by ctx.output.print(pstr(all_targets)). pstr here is used to
prettify the string representation of an object. We can see all the declared
targets, which correspond to the ones displayed in the target graph above:
[
root//:a (<unspecified>),
root//:b (<unspecified>),
root//:bin (<unspecified>),
root//:c (<unspecified>),
root//:d (<unspecified>),
root//:data_a (<unspecified>),
root//:e (<unspecified>)
]
Finally, we need to do a filter, we can use
ctx.cquery().kind to filter
the targets to only get the targets which is binary or library
nodes = ctx.cquery().kind("^(binary|library)$", all_targets)
ctx.output.print(pstr(nodes))
We run the bxl script and the output shows our filtered targets:
[
root//:a (<unspecified>),
root//:b (<unspecified>),
root//:bin (<unspecified>),
root//:c (<unspecified>),
root//:d (<unspecified>),
root//:e (<unspecified>)
]
Note that root//:data_a is no longer in the list, since it's a resource
target.
You can find the complete code for this tutorial in [part1.bxl](
https://github.com/facebook/buck2/blob/main/examples/bxl_tutorial/part1.bxl
).
Part 2
In this part, we'll extend our script to analyze the targets we filtered and extract their index information. We'll see how to work with analysis results and access sub-targets.
Let's continue with the script we made in Part 1. Let's get the analysis for these nodes:
analysis_res_dict = ctx.analysis(nodes)
This gives us a dictionary, where keys are target labels and values are of type AnalysisResult
Index data is in each target's "index"
sub-target's default_outputs, so iterate
through analysis_res_dict to get that:
index_outputs = []
for _, analysis_res in analysis_res_dict.items():
default_info = analysis_res.as_dependency()[DefaultInfo]
index_sub_target_provider = default_info.sub_targets["index"]
index_outputs.extend(index_sub_target_provider[DefaultInfo].default_outputs)
Let's see what's happening in each step:
- We create an empty list to store our index outputs
- We loop through each analysis result
- We get the DefaultInfo provider from each result
- We access the "index" sub-target
- Finally, we collect the default outputs from each index sub-target
Feel free to print each step's result to follow what the script is doing.
Finally, we print the results:
ctx.output.print(index_outputs)
You'll see output like this:
[
<build artifact a.index bound to root//:a (<unspecified>)>,
<build artifact b.index bound to root//:b (<unspecified>)>,
<build artifact bin.index bound to root//:bin (<unspecified>)>,
<build artifact c.index bound to root//:c (<unspecified>)>,
<build artifact d.index bound to root//:d (<unspecified>)>,
<build artifact e.index bound to root//:e (<unspecified>)>
]
You can find the complete code for this tutorial in [part2.bxl](
https://github.com/facebook/buck2/blob/main/examples/bxl_tutorial/part2.bxl
).
Part 3
In this part, we show how to run an action to write all the collected index paths to a file and materialize this index data. We show how to run actions and do materialization.
We'll build upon what we created in Part 2.
First, let's modify our script to write all the index paths to a file:
actions = ctx.bxl_actions().actions
index_db = actions.write("index.txt", index_outputs)
It creates the action object and then writes
all the index path to the file named index.txt.
With such, bxl will not run the action to get the output, it just declares the
action. We need to call
ctx.output.ensure to make
our outputs available.
ensured_index_db = ctx.output.ensure(index_db)
ctx.output.print(ensured_index_db)
Running the script will show us where our file was created:
buck-out/v2/gen-bxl/root/78ceb8c295d0ab4e/part3.bxl/__main__e0c0381aecee358a__/index.txt
We open this file and to see all the index paths:
buck-out/v2/gen/root/6dd044292ff31ae1/__a__/a.index
buck-out/v2/gen/root/6dd044292ff31ae1/__b__/b.index
buck-out/v2/gen/root/6dd044292ff31ae1/__bin__/bin.index
buck-out/v2/gen/root/6dd044292ff31ae1/__c__/c.index
buck-out/v2/gen/root/6dd044292ff31ae1/__d__/d.index
buck-out/v2/gen/root/6dd044292ff31ae1/__e__/e.index
It shows all the index path, but if we check the content of the index, it will not error that "no such file or directory". This is because we don't ensure the these artifacts.
So we ensure our index files to make them available:
ctx.output.ensure_multiple(index_outputs)
Now we can confirm these index files are available on our disk.
You can find the complete code for this tutorial in [part3.bxl](
https://github.com/facebook/buck2/blob/main/examples/bxl_tutorial/part3.bxl
).
Conclusion
In this tutorial, we built a complete BXL script that:
- Gets a target universe and filters for specific target types
- Extracts index information from build targets
- Writes the collected paths to a file and materializes the index files
Here's what we learned along the way:
- How to use target universes to get dependencies
- Filtering targets with cquery
- Analyzing targets and accessing their properties
- Running actions to write files
- Ensuring outputs are available on disk
The final script demonstrates a common BXL workflow: starting from a target, finding related targets, extracting information, and producing outputs. This pattern can be used as a foundation for building more complex BXL scripts.